Monitoring your Node
This comprehensive guide will assist you in effectively monitoring your Charon clusters and setting up alerts by running your own Prometheus and Grafana server. If you want to use Obol’s public dashboard instead of running your servers, refer to this section in Obol docs that teaches you how to push Prometheus metrics to Obol.
To explain quickly, Prometheus generates the metrics and Grafana visualizes them. To learn more about Prometheus and Grafana, visit here. If you are using CDVN repository or CDVC repository, then Prometheus and Grafana are part of docker compose file and will be installed when you run docker compose up.
The local Grafana server will have a few pre-built dashboards:
-
Charon Overview
This is the main dashboard that provides all the relavant details about the Charon node, for example - peer connectivity, duty completion, health of beacon node and downstream validator, etc. To open, navigate to
charon-distributed-validator-nodedirectory and open the followinguriin the browserhttp://localhost:3000/d/d6qujIJVk/. -
Single Charon Node Dashboard (deprecated)
This is an older dashboard Charon node monitoring which is now deprecated. If you are still using it, we would highly recommend to move to Charon Overview for most up to date panels.
-
Charon Log Dashboard
This dashboard can be used to query the logs emitted while running your Charon node. It utilises Grafana Loki. This dashboard is not active by default and should only be used in debug mode. Refer to advanced docker config section on how to set up a debug mode.
| Alert Name | Description | Troubleshoot |
|---|---|---|
| ClusterBeaconNodeDown | This alert is activated when the beacon node in a the cluster is offline. The beacon node is crucial for validating transactions and producing new blocks. Its unavailability could disrupt the overall functionality of the cluster. | Most likely data is corrupted. Wipe data from the point you know data was corrupted and restart beacon node so it can be synced again. |
| ClusterMissedAttestations | This alert indicates that there have been missed attestations in the cluster. Missed attestations may suggest that validators are not operating correctly, compromising the security and efficiency of the cluster. | This alert is triggered when 3 attestation are missed in 2 minutes. Check if the minimum threshold of peers are online. If correct, check for beacon node API errors and downstream validator errors using Loki. Lastly, debug from Docker using docker compose debug. |
| ClusterInUnknownStatus | This alert is designed to activate when a node within the cluster is detected to be in an unknown state. The condition is evaluated by checking whether the maximum of the app_monitoring_readyz metric is 0. | This is most likely a bug in Charon. Report to us via Discord. |
| ClusterInsufficientPeers | This alert is set to activate when the number of peers for a node in the cluster is insufficient. The condition is evaluated by checking whether the maximum of the app_monitoring_readyz equals 4. | If you are running group cluster, check with other peers to troubleshoot the issue. If you are running solo cluster, look into other machines running the DVs to find the problem. |
| ClusterFailureRate | This alert is activated when the failure rate of the cluster exceeds a certain threshold, more specifically - more than 5% failures in duties in the last 6 hours. | Check the upstream and downstream dependencies, latency and hardware issues. |
| ClusterVCMissingValidators | This alert is activated if any validators in the cluster are missing. This happens when validator client cannot load validator keys in the past 10 minutes. | Find if validator keys are missing and load them. |
| ClusterHighPctFailedSyncMsgDuty | This alert is activated if a high percentage of sync message duties failed in the cluster. The alert is activated if the sum of the increase in failed duties tagged with "sync_message" in the last hour divided by the sum of the increase in total duties tagged with "sync_message" in the last hour is greater than 10%. | This may be due to limitations in beacon node performance on nodes within the cluster. In charon, this duty is the most demanding, however, an increased failure rate does not impact rewards. |
| ClusterNumConnectedRelays | This alert is activated if the number of connected relays in the cluster falls to 0. | Make sure correct relay is configured. If you still get the error report to us via Discord. |
| PeerPingLatency | This alert is activated if the 90th percentile of the ping latency to the peers in a cluster exceeds 400ms within 2 minutes. | Make sure to set up stable and high speed internet connection. If you have geographically distributed nodes, make sure latency does not go over 250 ms. |
| ClusterBeaconNodeZeroPeers | This alert is activated when beacon node cannot find peers. | Go to docs of beacon node client to troubleshoot. Make sure there is no port overlap and p2p discovery is open. |
Setting Up a Contact Point
When alerts are triggered, they are routed to contact points according notification policies. For this, contact points must be added. Grafana supports several kind of contact points like email, PagerDuty, Discord, Slack, Telegram etc. This document will teach how to add Discord channel as contact point.
-
On left nav bar in Grafana console, under
Alertssection, click on contact points. -
Click on
+ Add contact point. It will show following page. Choose Discord in theIntegrationdrop down.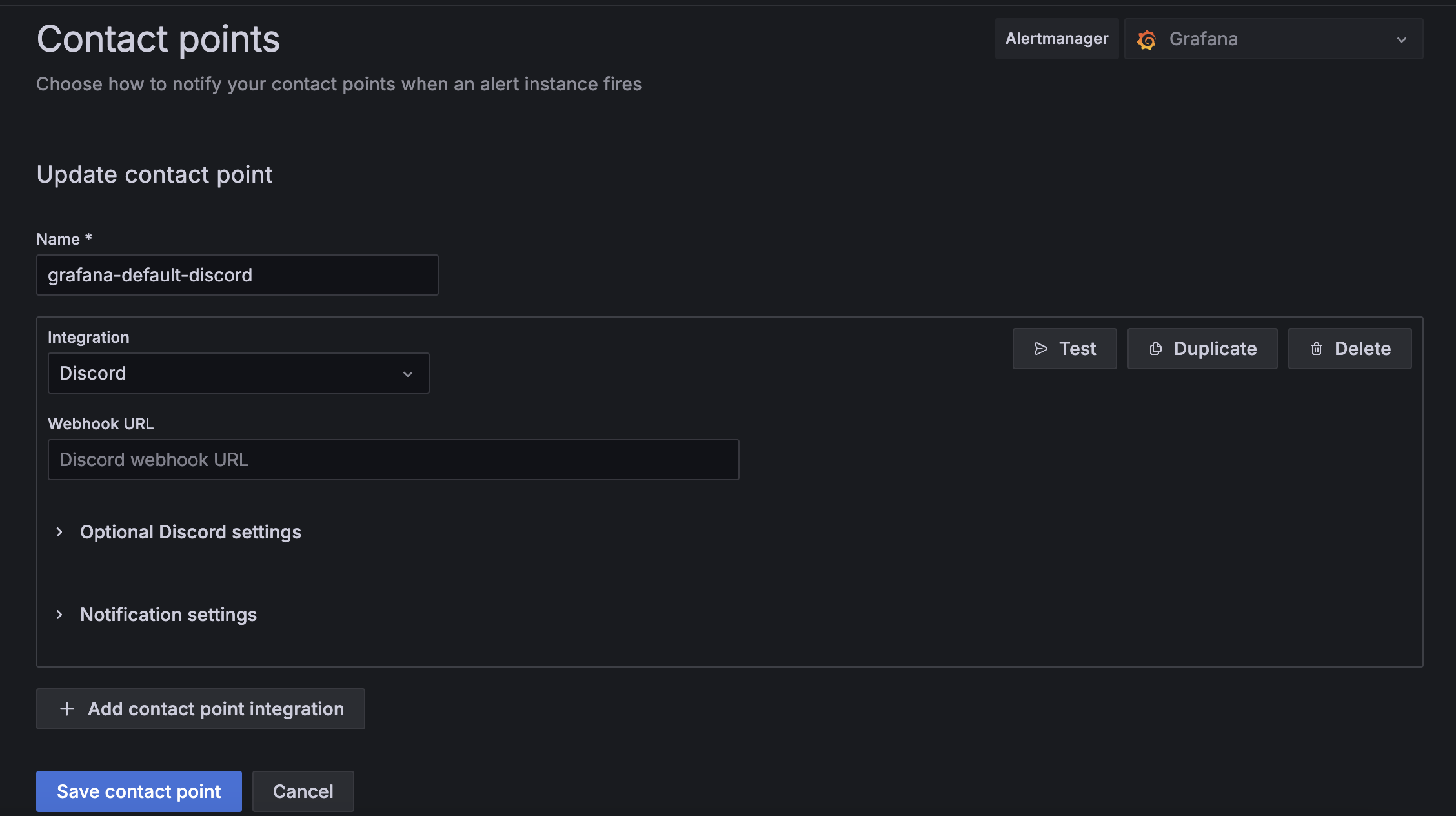
-
Give a descriptive name to the alert. Create a channel in Discord and copy its
webhook url. Once done, clickSave contact pointto finish. -
When the alerts are fired, it will send without filling in the variables for cluster detail. For example,
cluster_hashvariable is missing herecluster_hash = {{.cluster_hash}}. This is done to save disk space. To find the details, usedocker compose -f docker-compose.yml -f compose-debug.yml up. More description here.
Best Practices for Monitoring Charon Nodes & Cluster
- Establish Baselines: Familiarize yourself with the normal operation metrics like CPU, memory, and network usage. This will help you detect anomalies.
- Define Key Metrics: Set up alerts for essential metrics, encompassing both system-level and Charon-specific ones.
- Configure Alerts: Based on these metrics, set up actionable alerts.
- Monitor Network: Regularly assess the connectivity between nodes and the network.
- Perform Regular Health Checks: Consistently evaluate the status of your nodes and clusters.
- Monitor System Logs: Keep an eye on logs for error messages or unusual activities.
- Assess Resource Usage: Ensure your nodes are neither over- nor under-utilized.
- Automate Monitoring: Use automation to ensure no issues go undetected.
- Conduct Drills: Regularly simulate failure scenarios to fine-tune your setup.
- Update Regularly: Keep your nodes and clusters updated with the latest software versions.
Third-Party Services for Uptime Testing
Key metrics to watch to verify node health based on jobs
CPU Usage: High or spiking CPU usage can be a sign of a process demanding more resources than it should.
Memory Usage: If a node is consistently running out of memory, it could be due to a memory leak or simply under-provisioning.
Disk I/O: Slow disk operations can cause applications to hang or delay responses. High disk I/O can indicate storage performance issues or a sign of high load on the system.
Network Usage: High network traffic or packet loss can signal network configuration issues, or that a service is being overwhelmed by requests.
Disk Space: Running out of disk space can lead to application errors and data loss.
Uptime: The amount of time a system has been up without any restarts. Frequent restarts can indicate instability in the system.
Error Rates: The number of errors encountered by your application. This could be 4xx/5xx HTTP errors, exceptions, or any other kind of error your application may log.
Latency: The delay before a transfer of data begins following an instruction for its transfer.
It is also important to check:
- NTP clock skew;
- Process restarts and failures (eg. through
node_systemd); - Alert on high error and panic log counts.